Use the snowflake schema for hierarchical dimension tables
A snowflake schema is a variation on the star schema,
in which very large dimension tables are normalized into multiple
tables. Dimensions with hierarchies can be decomposed into a snowflake
structure when you want to avoid joins to big dimension tables when
you are using an aggregate of the fact table. For example, if you
have brand information that you want to separate out from a product dimension
table, you can create a brand snowflake that consists of a single
row for each brand and that contains significantly fewer rows than
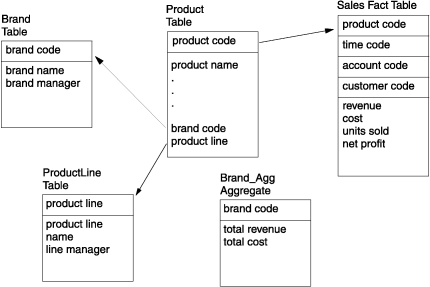
the product dimension table. The following figure shows a snowflake
structure for the brand and product line elements and the brand_agg aggregate
table. Figure 1: An example
of a snowflake schema
If you create an aggregate table, brand_agg, that consists
of the brand code and the total revenue per brand, you can use the
snowflake schema to avoid the join to the much larger sales table.
For example, you can use the following query on the brand and brand_agg tables:
SELECT brand.brand_name, brand_agg.total_revenue
FROM brand, brand_agg
WHERE brand.brand_code = brand_agg.brand_code
AND brand.brand_name = 'Anza'
Without a snowflaked dimension table, you use a SELECT UNIQUE or
SELECT DISTINCT statement on the entire product table (potentially,
a very large dimension table that includes all the brand and product-line
attributes) to eliminate duplicate rows.
While snowflake schemas are unnecessary when the dimension tables
are relatively small, a retail or mail-order business that has customer
or product dimension tables that contain millions of rows can use
snowflake schemas to significantly improve performance.
If an aggregate table is not available, any joins to a dimension
element that was normalized with a snowflake schema must now be a
three-way join, as the following query shows. A three-way join reduces
some of the performance advantages of a dimensional database.
SELECT brand.brand_name, SUM(sales.revenue)
FROM product, brand, sales
WHERE product.brand_code = brand.brand_code
AND brand.brand_name = 'Alltemp'
GROUP BY brand_name