Planning your server topology
The IBM Traveler server can be deployed using several different configurations. Considerations should be given to capacity and availability needs of the IBM® Traveler servers, location of mail servers, domain of mail servers and directory server compatibility.
IBM Traveler servers can be deployed as standalone servers, or if a highly available environment is required, as part of a pool of servers.
The standard IBM Traveler server configuration deploys as a single instance. An internal database is used to store synchronization state data. Administration data (for example, security compliance) is stored in the IBM® Traveler Domino® database. All of this data is known only to this instance of the server. This configuration is referred to as a stand alone server. It is possible to deploy multiple stand alone servers, however, each server operates independently and does not share information. What this means in practical terms is that if a user syncs with one stand alone server and then switches to another, the device is treated like a new device and must re-synchronize with the server. In a multi-server standalone environment, the users are load balanced administratively, assigning different URLs to different groups of users. It is possible to set up multiple IBM Traveler servers using a shared enterprise database. This configuration is referred to as a High Availability (HA) pool. In this configuration, all of the sync history and administration information for a device is stored in the enterprise database. This allows any server in the HA pool to be able to service requests from any user/device.
The advantage of deploying an HA pool configuration is the ability to balance the load of requests among the pool of servers, seamlessly add capacity, as well as start and stop servers for maintenance without impacting the availability for serving synchronization requests. A user's mail is monitored for changes only on one server in the HA pool. For maximum efficiency, all devices for a user are routed to the IBM Traveler server that is monitoring the mail for that user. In the event that a server becomes overloaded or unavailable, another server in the pool will takeover the responsibility for monitoring a user's mail and device requests will be rerouted.
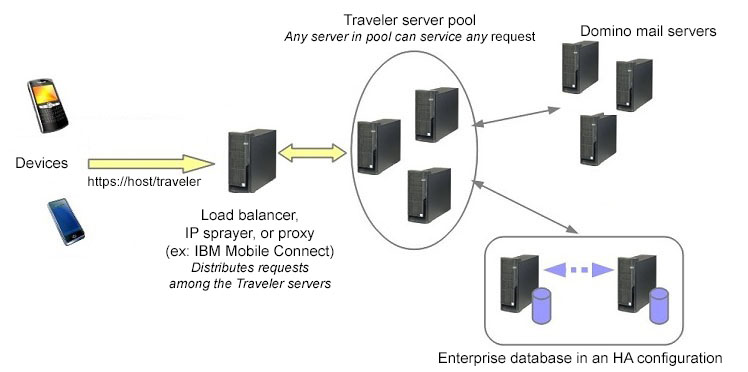
There are configuration architecture requirements with an HA pool. An HA pool requires a front end service that can provide a single URL entry point and evenly spread requests across the HA pool. This typically can be provided by some form of an IP Sprayer. This allows all devices to be configured for the same address without regard to a specific server that may process the request. The sprayer detects when a IBM Traveler server becomes unavailable and then routes requests to other servers. No additional load balancing functions are required, as the IBM Traveler servers handle the load balancing amongst the servers in the pool. Servers in an HA pool should be co-located to avoid network latency issues that could affect server to server communication, server to database communication, as well as server to mail server communication. Each component of the configuration should have a redundant counter part to avoid single points of failures. Likewise, multiple components should not be deployed on the same physical server (for example, IBM Traveler server and the database server).
Which configuration to choose depends upon availability requirements, infrastructure costs, and geographic requirements. If continuous availability is required, then an HA pool is the best configuration. For smaller deployments, stand alone servers may still be sufficient. If IBM Traveler access needs to be geographically dispersed, a single HA pool is not recommended due to network latency issues. In that kind of environment, stand alone servers or multiple HA pools will be needed. Stand alone servers can be added to an HA pool such that a configuration can grow from a stand alone server configuration into a highly available configuration.
For more information on failover and clustering, see Clustering and failover.